
그로스&퍼포먼스 마케팅
코호트분석(COHORT)이란? 본문
코호트 분석은 사용자 행동을 그룹으로 나눠 지표별로 수치화한 뒤 분석하는 기법
단순히 말하면, 시간을 두고 비슷한 그룹을 비교하는 것입니다.
인터넷 쇼핑몰을 예로 들면, 판매개시 1개월차에 가입한 고객들과 6개월차에 가입한 고객들의
사용경험이나 매출,탈퇴율등의 지표는 분명히 다를 것입니다.
이때, 여러 단계로 나누어져 있는 사용자 그룹이 각각 코호트그룹이 되는데,
예시를 보면,
| 1월 | 2월 | 3월 | 4월 | 5월 | |
| 전체 고객(명) | 1,000 | 2,000 | 3,000 | 4,000 | 5,000 |
| 고객당 평균 매출 | $5.00 | $4.50 | $4.33 | $4.25 | $4.50 |
그룹을 나누지 않고 전체 고객으로 바라보면 사업의 현황이 애매하게 보입니다.
고객은 증가하고 있지만, 평균매출이 줄어드는 건지 회복되는 건지가 모호하기 때문입니다.
그렇기에 신규고객과 기존고객들을 분리하여 분석해야합니다.
| 1월 | 2월 | 3월 | 4월 | 5월 | |
| 신규 사용자 | 1,000 | 1,000 | 1,000 | 1,000 | 1,000 |
| 전체 사용자 | 1,000 | 2,000 | 3,000 | 4,000 | 5,000 |
| 1개월 | $5.00 | $3.00 | $2.00 | $1.00 | $0.50 |
| 2개월 | $6.00 | $4.00 | $2.00 | $1.00 | |
| 3개월 | $7.00 | $6.00 | $5.00 | ||
| 4개월 | $8.00 | $7.00 | |||
| 5개월 | $9.00 |
같은 쇼핑몰의 데이터지만 고객층을 가입시기에 따라 나누어서 보았습니다.
1월의 신규가입자들은 평균 5달러의 매출을 보여주지만,
5월의 신규가입자들은 평균 9달러의 매출을 보여줍니다.
점점 신규가입자들의 매출이 증가하는 것이 보입니다.
신규가입자의 증가와 구매액증가가 명확히 보이고 있는데, 이는 온라인쇼핑몰에서 긍정적인 사업지표로 볼 수 있습니다.
여기서 비즈니스관점으로 보았을때 주의해야 될 점은,
1) 초기가입자들의 구매액감소
2) 신규가입자의 증가폭 개선
등이 있습니다.
예시처럼 지표들이 확연하게 보일수도 있지만, 사업종류나 형태에 따라
코호트의 기준을 다르게 할 수도,해석을 다르게 할 수도 있다는 것에 주의해야 할 것입니다.
또한, 예시처럼 구매액기준이 아닌 방문율이나 재구매율을 판단지표로 삼을수도 있습니다.
이제, 실제 파이썬분석을 통해 실습해보겠습니다.
데이터 전처리

사용 데이터 :
Online Retail List for RFM
https://www.kaggle.com/datasets/ilkeryildiz/online-retail-listing?resource=download
Online Retail List for RFM
Online Retail List for RFM
www.kaggle.com
사용데이터에는 가입시기가 없고 구매일이 있기때문에,
고객별 첫구매시기를 기준으로 코호트 분석을 진행하겠습니다.
# 필요없는 칼럼 삭제
df = df.drop(['StockCode','Invoice','Description','Quantity','Country'],axis=1)
# 날짜 형식 변환
df['InvoiceDate'] = pd.to_datetime(df['InvoiceDate'])
# 날짜형식 월별로 변환
df['InvoiceDate']=df['InvoiceDate'].dt.strftime('%Y.%m')
이번 코호트 분석에서는 재구매율(재방문율)과 매출만 분석하기에 필요없는 컬럼은 모두지워줍니다.
구매시기,가격,고객ID만 남겨줍니다.
또한, 코호트분석을 위해서는 구매시기가 날짜형식으로 되어있는 것이 매우중요합니다.
datetime() 함수로 날짜형식으로 변경한뒤 dt.strftime() 함수로 형식을 년월만 표시하도록 합니다.
구매시기, 구매금액 계산
## 구매시기 계산
# Group by를 통한 첫 구매일 계산
first_order = df.groupby('Customer ID').InvoiceDate.min()
first_order = pd.to_datetime(first_order).dt.strftime('%Y.%m')
first_order.head()
# 'FirstOrder' 열을 datetime 형식으로 변환
df['FirstOrder'] = pd.to_datetime(df['FirstOrder'])
# 'InvoiceDate' 열을 datetime 형식으로 변환
df['InvoiceDate'] = pd.to_datetime(df['InvoiceDate'])
# 2010년 데이터만 필터링
df = df[df['FirstOrder'].dt.year == 2010]
df = df[df['InvoiceDate'].dt.year == 2010]
# 'FirstOrder' 열에서 연도와 월까지만 나타내도록 포맷 변경
df['FirstOrder'] = df['FirstOrder'].dt.strftime('%Y-%m')
# 'InvoiceDate' 열에서 연도와 월까지만 나타내도록 포맷 변경
df['InvoiceDate'] = df['InvoiceDate'].dt.strftime('%Y-%m')
print(df.head())
분석을 위해, 고객ID ( 고객 ) 별 첫 구매시기를 계산해주고 새로운 열로 추가합니다.
또한, 이번분석에서는 1년만 보기위해서 2010년 데이터만 필터링해주었습니다.
## 구매금액계산
# 공백없애기
df.rename(columns={'Customer ID': 'CustomerID'}, inplace=True)
# Price 열 데이터형식 변경
df['Price']=df['Price'].astype('float')
## 주기별 구매 User 계산
co1 = df.groupby(['FirstOrder', 'InvoiceDate']).CustomerID.nunique()
co1 = co1.reset_index()
co1.rename({'CustomerID': 'TotalUsers'}, axis = 1, inplace = True)
## 주기별 구매 금액 계산
co2 = df.groupby(['FirstOrder', 'InvoiceDate']).Price.sum()
co2 = co2.reset_index()
co2.rename({'TotalCharges': 'PurchaseAmnt'}, axis = 1, inplace = True)
## 데이터의 병합
co = co1.merge(co2, on = ['FirstOrder', 'InvoiceDate'])
co
구매금액을 계산하기전에
Customer ID 열이름이 공백이 존재해 오류가 생겨 제거해주었으며,
Price열을 실수형으로 변경해주었습니다.
코호트 분석을 위해, 주기별로 구매고객의 수와 구매금액을 계산해주었습니다.
코호트 분석
from ipypb import ipb
temp = [] # 빈 시리즈 생성
for i in ipb(range(co.shape[0])):
f_first_order = pd.to_datetime(co.FirstOrder[i]).to_period('M') # 월단위로 변경
f_order_cycle = pd.to_datetime(co.InvoiceDate[i]).to_period('M') # 월단위로 변경
month_diff = (f_order_cycle - f_first_order).n # 구매월과 첫구매월차이 계산
temp.append(month_diff) # temp에 데이터추가
co['CohortPeriod'] = temp # CohortPeriod 열 생성
코호트열을 만들어주기위한 반복문입니다.
이 경우에는 구매월끼리의 차이를 나타내는 열을 자동으로 계산해주는 함수를 만들었습니다.
## 재방문율 계산
co_retention = co.set_index(['FirstOrder', 'CohortPeriod'])
co_retention = co_retention.TotalUsers.unstack(1)
retention = co_retention.div(co_retention[0],axis = 0)
# 구매액 형식 변경
co_purchase = co.set_index(['FirstOrder', 'CohortPeriod'])
co_purchase = co_purchase.Price.unstack(1)
데이터계산을 위해 unstack을 활용하였습니다.
인덱스를 첫구매월,코호트기간으로 설정한뒤,
unstack을 사용하면, 인덱스를 컬럼으로 변경해줍니다. unstack(1)이므로, 코호트기간이 컬럼이 되며 재정렬됩니다.
그후 , 각 행의 값(구매월마다의 방문자) 을 첫 행의 값(첫구매월의 방문자)으로 나누어 재방문율을 계산합니다.

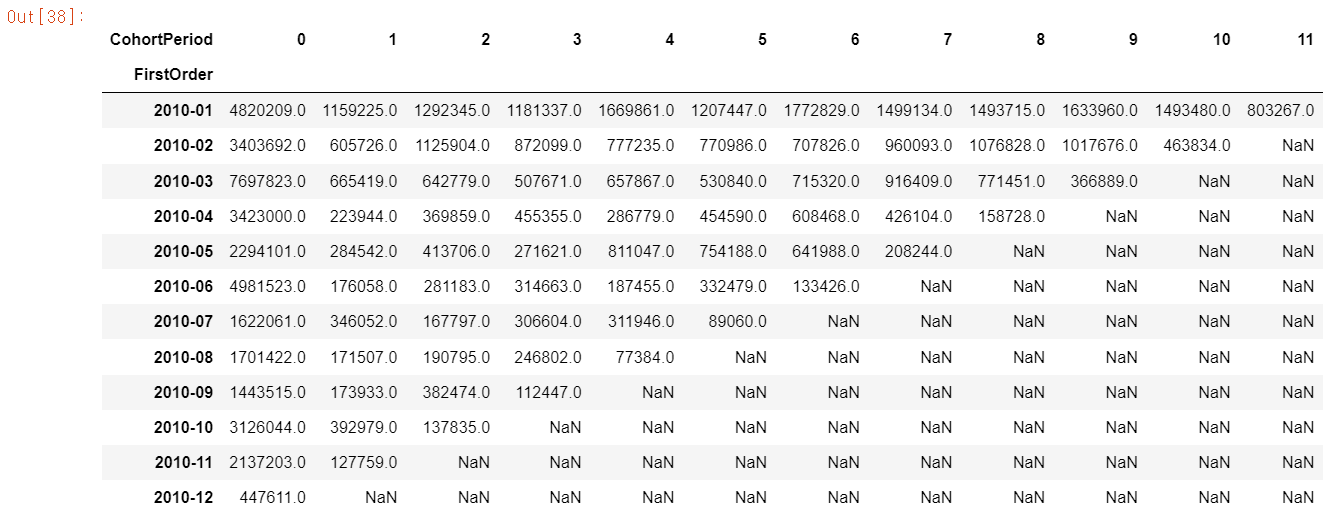
이제 코호트분석에 활용할 표가 만들어졌습니다.
값으로 보아도 좋지만, 더 직관적으로 확인을 위해 시각화까지 해보겠습니다.
import matplotlib.pyplot as plt
import seaborn as sns
## 재방문율 시각화 진행
plt.rcParams['figure.figsize'] = (12, 8)
sns.heatmap(retention, annot=True, fmt='.0%') # 재방문율 표시 포맷 수정
plt.yticks(rotation=360)
plt.show()

가장많이 사용하는 seaborn 라이브러리의 heatmap을 사용했습니다.
이제부터가 진짜 코호트 분석의 시작입니다.
이것을 가지고 어떤시각으로 어떻게 해석할지가 중요합니다.
몇가지 관점으로 바라보자면,
1) 2010년 1분기보다 3,4분기의 신규고객들은 바로 그 다음달에 재구매율이 유의미하게 낮다.
-> 1분기 고객들과 3,4분기고객들의 특성분석
2) 1,2,3월의 신규고객들은 오랜기간이 지나도 꽤 높은 재구매율을 유지하고 있다.
-> 1분기 고객들의 특성분석
3) 11월에는 전반적인 고객들의 구매율이 높았다
-> 판매데이터 분석
코호트분석자체가 주는 것은 단서일뿐입니다.
이것으로 주안점을 찾고 추가적인 분석으로 인사이트를 얻어내는 것이 더 중요하다고 할 수 있습니다.
